1 嵌入式代码开发
1.1 开发编译器
开源的sdcc编译器,一个优化的ansi-c交叉编译器。
2 常见接口引脚定义
USB协议官网:https://www.usb.org/
USB接口种类:https://zhuanlan.zhihu.com/p/447595295
常见USB引脚定义:https://zhuanlan.zhihu.com/p/364748197
USB 2.0 A型、B型、Mini和Micro接口 type-c 定义及封装:https://blog.csdn.net/wuhenyouyuyouyu/article/details/52511925
接口速率总结:
- USB3.0:460MB左右
- USB2.0:44MB左右
- Type-C:1GB左右
2.1 Type-C接口
https://blog.csdn.net/qlexcel/article/details/117431413
2.2 mini usb接口
https://blog.csdn.net/eddy_liu/article/details/8316140
| 针脚 | 1 | 2 | 3 | 4 | 5 |
|---|
| 名称 | VCC | D- | D+ | id | GND |
| 作用 | +5V电压 | 数据线负极 | 数据线正极 | OTG功能 | 接地 |
| 接线颜色 | 红色 | 白色 | 绿色 | / | 黑色 |
2.3 充电DC圆孔
无论是公口或者母口,一般都是内正外负,不仅是5.5大小的,4、3.5、2.5等等的。不过有些厂家是对着干的,比如当年卡西欧和雅马哈电子琴所配的电源。
![]()
DC接口引脚定义
3 常见传感器的应用
- IR感测器(红外):作为检测判断防尘网是否被灰尘堵塞(用例:华硕PA602机箱)
- 触摸传感器(触觉传感器):对于触摸或者压力敏感, 是一种用来检测物体接触或靠近的传感器。通常是通过检测触摸界面的电容或电阻的变化,或者是检测声波反射等方式来工作。
- 电容式触摸传感器:弹簧型传感器,可适用于曲面前面板方案。例如屏幕灯为圆柱形,触摸面为曲面。
- 电阻式触摸传感器
- 红外触摸传感器
![]()
触摸传感器比较
4 华硕主板灯控开发
5 锂电池
- 串并联符号:串联s,并联p。3s1p:三串一并,一并实际就是没有并联。比如1s1p就是单一电池。
- 串联增压,并联增容。
- 18650久放失电时,若电池组电压过低,充电板不一定能识别到电池组,充电板的管理芯片可能存在电压判断逻辑,使用可调电源分别对每组18650电池组先充一会儿电量,让其恢复一点电压,然后再重新将鳄鱼夹夹到充电板上看看是否能正常充电。
6 FPC的断裂修复
刮表层,使用焊油连接金属触点(将锡附着在焊头上)。
7 蓝牙耳机拆解
8 焊接总结
- USB接口固定引脚的加固:一般的USB接口有两个的固定引脚,如果只在一侧加焊的话,USB接口的固定引脚仍有可能会因为长期的拔插使用导致断裂(是在没有焊点的那侧断裂的)。因此加固建议是在无焊点那侧加焊,即固定引脚两侧都有焊点。
- 5V3针灯条的串接,上下相叠起来才能吃锡
- 芯片主控板焊盘不需要值球(若买的成品焊盘已有值球的话,清理干净再上芯片),芯片需要值球。推荐吹焊前,先在焊盘均匀涂抹少许焊油。
- BGA封装的植球焊接
- 使用锡泥植球时,使用热风枪加热到锡泥变亮即加热成功(这个阶段一般不需要加焊油)。
- 倘若锡泥涂抹过多,导致加热后锡球不好脱离钢网的话,可以使用镊子夹起钢网,再重新加热,并利用重力让锡球脱离钢网。
9 U盘的拆解
9.1 推拉U盘的拆解
![]()
金士顿推拉U盘示意图
大部分推拉U盘的拆解,直接将推拉外壳往外使劲一拉就能拆掉。但这种拆卸方法可能会导致外壳内侧的突起卡扣点被破坏,从而导致安装回去的推拉外壳内侧没有卡点导致失去原来的推拉限位功能。
有帖子教学无损拆解,是使用订书钉或者回形针(钳子拉直)插到外壳两侧的条形凹槽,然后将推拉外壳退回最内侧,使长针卡进外壳内侧,然后将外壳往外使劲一拉。
在拆掉推拉外壳之后,内部塑料壳就是基础的四侧卡扣结构,直接从USB口那侧用撬片撬开人字形后,就可取出U盘的PCB板。
10 电热水壶
10.1 米家恒温电水壶,烧开后无法断电
11 参考文献
[1] 触摸传感器 - 从零开始认识各种传感器【第五期】[EB/OL]. https://blog.csdn.net/m0_61036291/article/details/140498200.
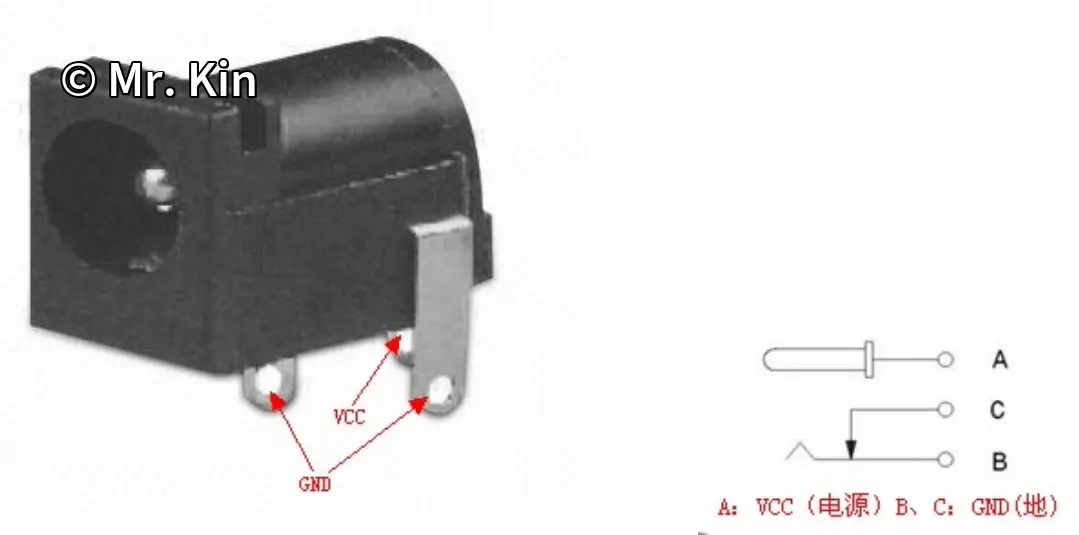 DC接口引脚定义
DC接口引脚定义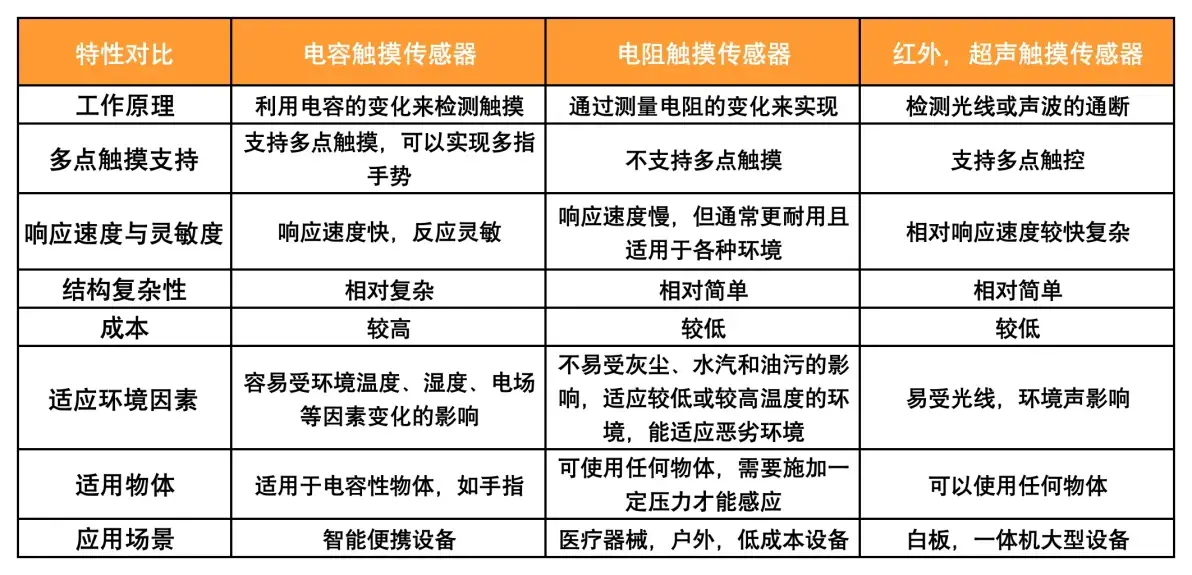 触摸传感器比较
触摸传感器比较 金士顿推拉U盘示意图
金士顿推拉U盘示意图